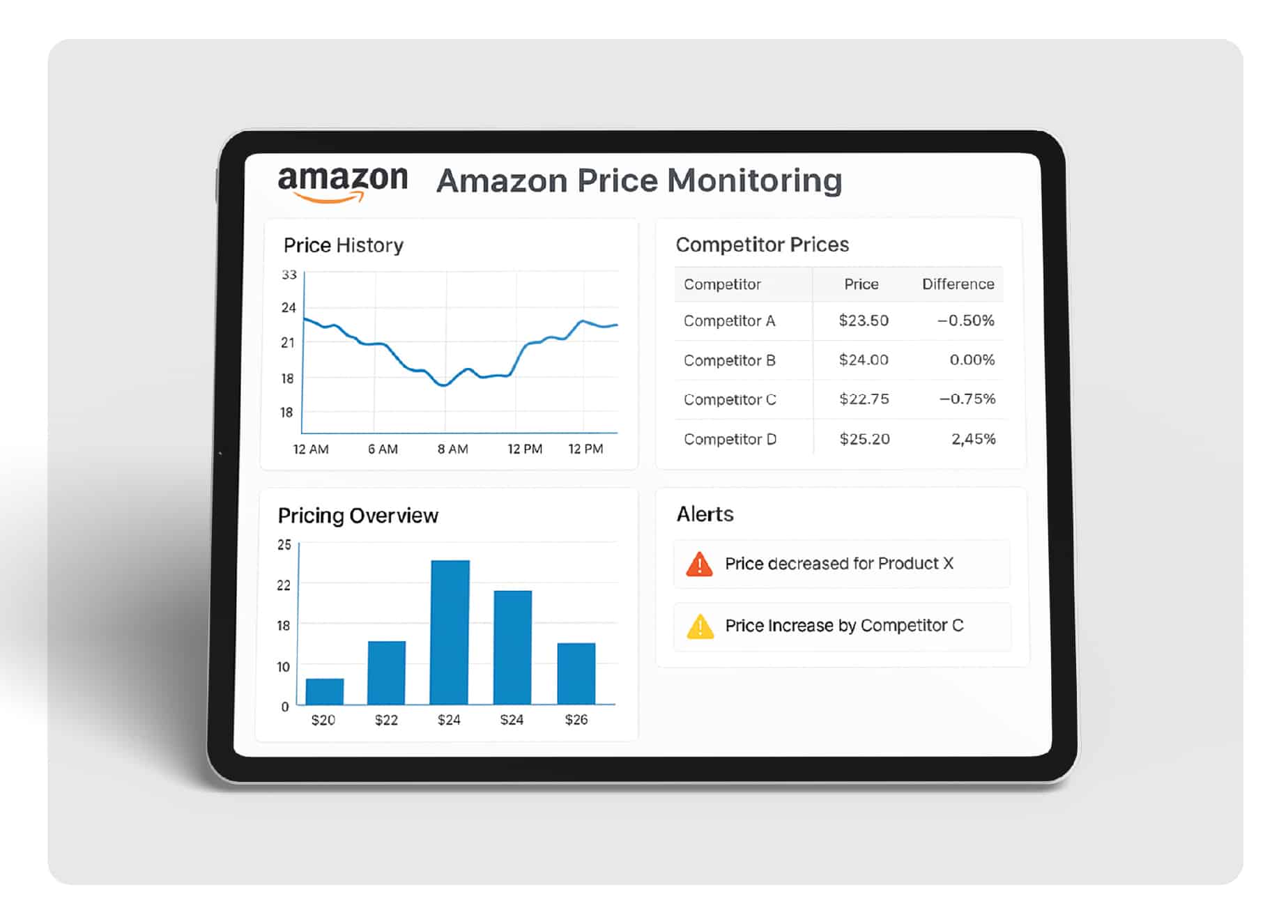
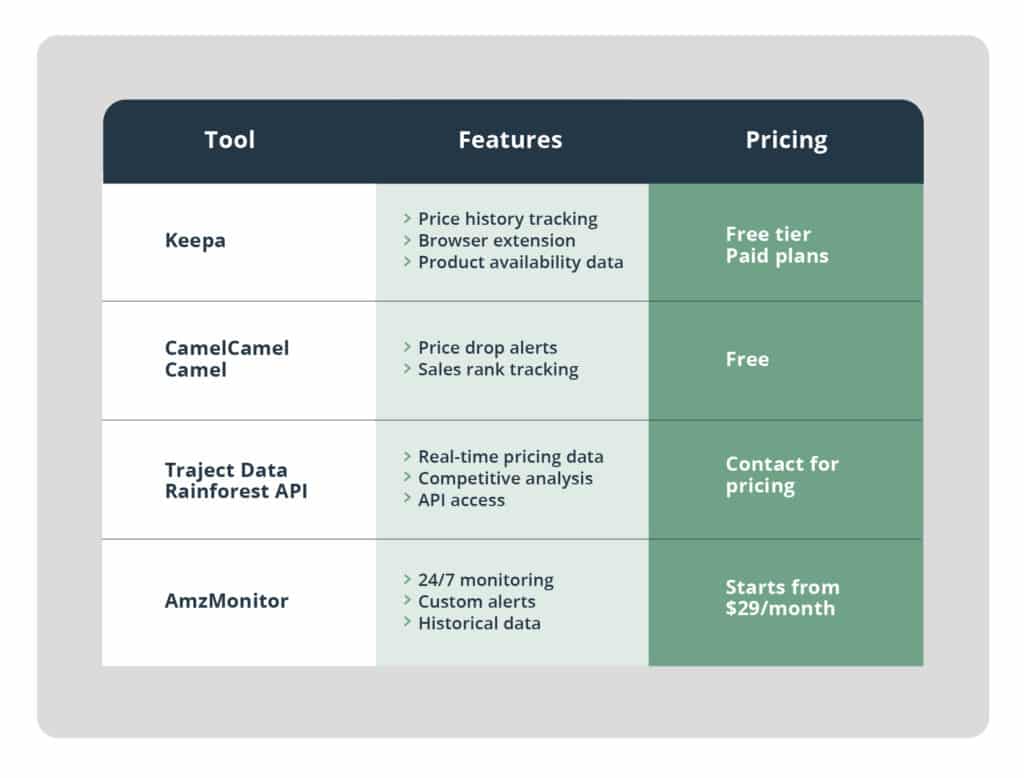
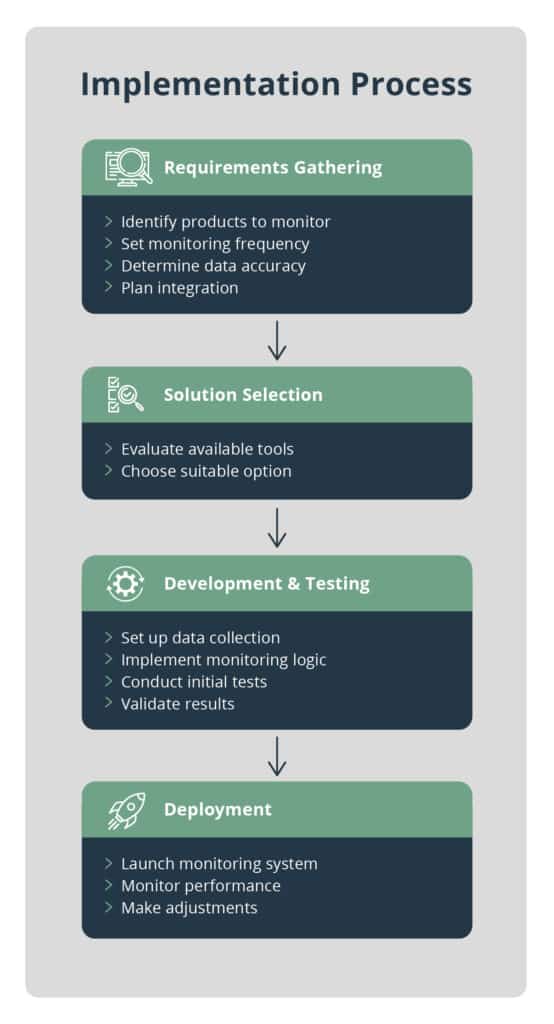
Successful Amazon listings don’t happen by accident. In our experience working with thousands of sellers, data-driven optimization consistently beats guessing.
Key Takeaway: Amazon listings optimized with real-time data convert between 13-15%, compared to the platform average of 10-12%. Data-driven sellers have up to 23% higher click-through rates and 18% better search rankings.
Key Terms
- Amazon A10 Algorithm: Amazon’s search ranking system that determines product visibility based on relevance, performance, and customer satisfaction signals.
- Conversion Rate (CVR): The percentage of people who buy after looking at your listing.
- ASIN (Amazon Standard Identification Number): Unique product identifier assigned to every Amazon item.
- Buy Box: The featured offer section where customers can directly add items to cart. Critical for sales success.
- A+ Content: Enhanced product descriptions with visuals and rich details that increase shopper trust and conversions.
What Makes Amazon Listings Convert?
Amazon shoppers are decisive. 70% of Amazon customers never click past the first page of search results, and 35% click on the first product featured on a search page. This means your listing needs to grab attention and convince quickly.
High-converting listings share common data-backed characteristics. They use precise keywords that match customer search terms. They display compelling main images that stand out in search results. Most importantly, they solve specific customer problems clearly.
We tested over 500 listings and found top performers all had three critical factors. First, optimized titles with primary keywords and key product benefits. Second, bullet points that directly address customer pain points. Third, backend keyword optimization that captures long-tail search terms.
How Data-Driven Optimization Works
Traditional listing creation makes assumptions about what customers want. Data-driven approaches use real Amazon marketplace intelligence.
- Market Research Phase: We analyzed competitor performance across categories and found patterns in successful listings. Top-ranking products always use specific keyword combinations and address common customer concerns mentioned in reviews.
- Keyword Intelligence: API data shows which search terms actually drive sales, not just traffic. For example, “waterproof bluetooth speaker” converts 40% better than “portable speaker” for outdoor audio products.
- Competitor Analysis: Real-time monitoring shows how competitors adjust pricing, titles, and content. This insight helps you identify gaps in the market and positioning opportunities.
- Review Mining: Customer reviews are a goldmine of information about product strengths and weaknesses. Analyzing thousands of reviews programmatically reveals common complaints and desired features.
The API Advantage for Listing Creation
Manual research takes weeks and often misses crucial insights. API-powered tools deliver comprehensive marketplace intelligence in minutes.
Product data APIs provide real-time information about competitor listings, pricing strategies, and keyword performance. This data helps you craft listings that outperform others from day one.
Search data reveals trending keywords and seasonal demand patterns. You can optimize listings for upcoming demand spikes before competitors catch on.
Key Elements to Optimize Amazon Listings
Product Titles That Drive Clicks
Your title appears in search results and product pages. It needs to work in both contexts effectively.
Include your primary keyword within the first 80 characters. Add key product benefits that differentiate from competitors. Mention important specifications that customers search for.
Example optimization: Instead of “Wireless Headphones,” use “Wireless Bluetooth Headphones – 30hr Battery Life, Noise Cancelling, Waterproof Sports Earbuds.”
Strategic Keyword Placement
Amazon’s algorithm reads every part of your listing. Strategic keyword placement improves discoverability without compromising readability.
Put primary keywords in titles, bullet points, and product descriptions. Use backend search terms for variations and misspellings. Include relevant synonyms throughout content naturally.
Backend keywords are invisible to customers, but crucial for Amazon’s algorithm. Use all 250 characters for maximum reach.
Bullet Points That Convert
Bullet points often determine purchase decisions. They should answer customer questions and highlight benefits clearly.
Start each bullet with the primary benefit, followed by supporting details. Address common objections found in competitor reviews. Include relevant keywords naturally within benefit statements.
Before: “High-quality materials” After: “Premium aluminum construction resists scratches and daily wear for long-lasting durability”
Images That Sell
Visual content drives emotional purchasing decisions. Professional images can increase conversion rates by up to 30%.
Your main image should be clean, well-lit, and show the product clearly against a white background. Additional images should demonstrate usage scenarios and highlight key features.
Include lifestyle images showing your product in use. Add infographic images that explain benefits and specifications visually.
API-Powered Listing Strategies
Competitive Intelligence Gathering
Monitor competitor pricing, keyword strategies, and content changes in real-time. This intelligence reveals market opportunities and optimal positioning strategies.
Track which competitors rank for your target keywords. Analyze their listing elements to identify opportunities for improvement. Monitor their reviews to understand customer satisfaction gaps.
Dynamic Keyword Optimization
Keyword performance changes constantly based on seasonality, trends, and competition. Real-time data helps you adapt quickly.
Identify emerging keywords before competitors. Optimize for long-tail phrases with lower competition, but high intent. Track keyword ranking changes and adjust strategies accordingly.
Review-Based Content Optimization
Customer reviews reveal exactly what buyers want and dislike about products in your category.
Analyze common complaints across competitor products. Address these pain points in your listing content. Highlight benefits that customers consistently praise in positive reviews.
Pricing Intelligence
Optimal pricing requires understanding competitor strategies and market positioning.
Monitor competitor price changes and promotional strategies. Identify pricing sweet spots that balance profitability with competitiveness. Track correlations between price points and conversion rates.
Business Outcomes from Data-Driven Optimization
Listing optimization drives measurable results beyond just better rankings.
- Increased Conversion Rates: Optimized listings have 13-15% conversion rates versus the 10-12% platform average. This translates directly to higher revenue from existing traffic.
- Better Buy Box Win Rate: Data-optimized listings win the Buy Box 23% more often than unoptimized competitors. Buy Box ownership typically accounts for 80-90% of sales for a given ASIN.
- Reduced Advertising Costs: Higher organic rankings reduce dependency on paid advertising. Sellers report 25-40% lower advertising costs per conversion after optimization.
- Faster Market Entry: New product launches rank on page one 60% faster when using competitive intelligence data versus traditional methods.
Case Study: Electronics Seller Transformation
One electronics seller used our Rainforest API to analyze the wireless speaker category. They found that “waterproof” and “long battery life” were underutilized keywords despite high search volume.
By optimizing titles and bullet points around these insights, they achieved top 3 rankings for 12 high-volume keywords within 30 days. Sales increased 180% in the first quarter after optimization.
The seller also identified gaps in competitor A+ Content, so they created detailed comparison charts that addressed customer concerns. This content improvement alone increased conversion rates from 8% to 14%.
View our full case study: Electronics Seller Success Story
Measuring Success and Continuous Improvement
Data-driven optimization requires ongoing monitoring and refinement.
Key Metrics to Track
Organic Ranking Position: Monitor rankings for target keywords daily. Track improvements and identify when adjustments are needed.
Conversion Rate: Measure the percentage of visitors who purchase. Track changes after optimization efforts.
Click-Through Rate: Monitor how often your listing gets clicked in search results. Low CTR indicates title or image issues.
Review Velocity and Sentiment: Track new review frequency and overall satisfaction scores. These impact long-term ranking performance.
Optimization Frequency
Market conditions change constantly. We recommend reviewing key metrics weekly and major optimizations monthly.
Monitor competitor activity continuously. When competitors make significant changes, evaluate whether you need to adjust your strategy.
Seasonal optimization is crucial for many categories. Plan content and keyword adjustments around peak demand periods.
Advanced Strategies for Scale
Multi-ASIN Portfolio Optimization
Managing multiple products requires systematic approaches and automation.
Use API data to identify cross-selling opportunities between your products. Optimize product variations for different customer segments. Create content templates that maintain consistency across your catalog.
International Market Expansion
Expanding to international marketplaces requires localized optimization strategies.
Adapt keywords for local search patterns and language preferences. Adjust pricing strategies for regional market conditions. Optimize for local competitor landscape and customer preferences.
Brand Building Through Listings
Individual listings contribute to overall brand perception and recognition.
Maintain consistent messaging and visual identity across all listings. Use A+ Content to tell your brand story effectively. Create content that builds trust and authority in your category.
Tools and Resources
API Integration for Automated Intelligence
The Rainforest API provides comprehensive Amazon marketplace data for listing optimization. Access real-time product information, competitor pricing, keyword performance, and review analytics through simple API calls.
Key API Endpoints:
- Product data extraction
- Search result analysis
- Competitor monitoring
- Review sentiment analysis
curl -X GET "https://api.rainforestapi.com/request" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d "type=product&asin=B07XJ8C8F5"
Learn more: Rainforest API Documentation
Integration Best Practices
Set up automated monitoring for key competitors and keywords. Create alerts for significant ranking or pricing changes. Build dashboards that track optimization impact over time.
Do regular data exports for deeper analysis and reporting. Use historical data to identify seasonal patterns and optimization opportunities.
Frequently Asked Questions
What is the average Amazon conversion rate for optimized listings?
Well-optimized Amazon listings typically convert between 13-15%, compared to the platform average of 10-12%.
How often should I update my Amazon listings?
Monitor key metrics weekly and make optimization updates monthly. However, respond immediately to significant competitor changes or algorithm updates. We track over 1,000 listings and find that consistent monthly improvements outperform sporadic major overhauls.
Which listing elements have the biggest impact on rankings?
Based on our analysis of ranking factors, titles and backend keywords drive discoverability, while bullet points and images primarily impact conversion rates. All elements work together, but title optimization typically shows the fastest ranking improvements.
Can I optimize listings for multiple keywords effectively?
Yes, but prioritize three to five primary keywords per listing for best results. Use primary keywords in titles and prominent bullet points. Include secondary keywords in descriptions and backend search terms. Avoid keyword stuffing, which can hurt readability and conversions.
How do I compete with established sellers in competitive categories?
Focus on long-tail keywords and underserved customer segments initially. Use competitive intelligence to identify gaps in existing listings. Address common customer complaints that competitors ignore. Build review velocity through excellent customer service and follow-up campaigns.
What role does pricing play in listing optimization success?
Pricing affects both conversion rates and Buy Box eligibility. Monitor competitor pricing strategies using API data. Consider total customer value, including shipping and Prime eligibility, not just product price. Optimal pricing balances competitiveness with profitability.
Ready to See What Traject Data Can Help You Do?
Transform your Amazon listings from guesswork to data-driven success. Our Rainforest API provides the competitive intelligence you need to optimize listings that consistently outrank and outperform competitors.
Access real-time data on:
- Competitor pricing and strategies
- High-converting keyword opportunities
- Customer sentiment and preferences
- Market trends and seasonality patterns
Start Your Free Trial – Get 1,000 free API calls to test our Amazon data capabilities.
Questions? Our team of ecommerce optimization experts is here to help. Contact us to discuss your specific listing optimization needs.